
How does web cache work?
In order to reduce the HTTP requests latency and reduce the performance stress of the application servers, an web application would have some web data, for example, images, js files, css file, HTML context files, json template, URLs copied and stored in a different storage or place (your browser, proxy server or a CDN)for a certain amount of time, we call it Cache. After these data are stored in Cache, these cached web data could be served to some users directly rather than asking the application servers to extract data over and over again when users are making requests to these data.
In general, web cache could be categorized as client side cache ( browser cache) or remote server side cache (Proxy, CDN). The data stored in the browser will only serve the local user when using that browser; whereas, the cached data on the server side will be distributed and served to many users.
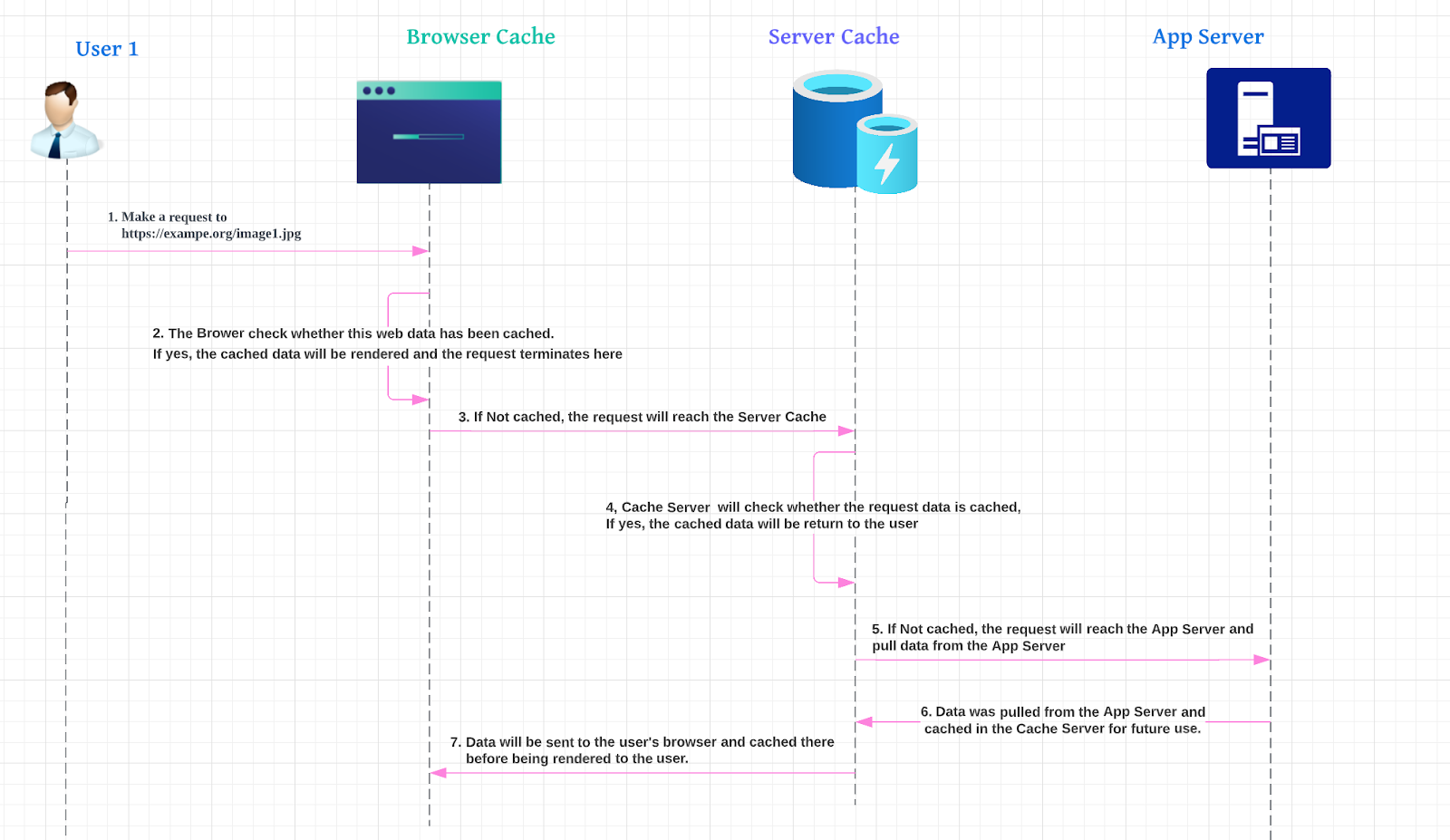
The diagram below depicts how Client Side Cache and Server Side Cache work in a web request, and how App Server could reduce the requests by utilizing cache.
Security Issues in Web Cache
Web caching improves performance and convenience, but it has a drawback: security.
Security issues in client side Cache(Browser Cache)
The risk with browser side caches is that you may leave sensitive information on a browser cache. Users with access to the same browser could steal the cached data. Risks are more likely to occur in public terminals, such as those found in libraries and Internet cafes. In this article, we will focus more on the security issues on the server side cache.
Security Issues in the server side cache
The most common security issues discovered in the web cache are Web Cache Deception and Web Cache Poison. Web cache deception is when an attacker tricks a caching server into incorrectly storing the victim’s private information, and then the attacker gains access to the cached data by accessing the cache server. In contrast, web cache poisoning is an attack in which a malicious user stores malicious data in the web cache server, and the malicious data is distributed to many victims by the cached server.
Difference between Web Cache Deception and Web Cache Poison
Engineers are frequently perplexed by the terms Web Cache Deception and Web Cache Poison. Let’s use the table below to tell the difference between web cache deception and web cache poison.
| Which data are cached? | How does an exploit happen? | Is Interaction required? | |
| Cache Deception | Victim’s private data unconsciously stored | 1. An attacker impersonates a path within an application, such as http://example.org/profile.php/noexistening.js, and causes the victim to click on the link. 2. Assuming the victim has logged in and the profile.php page contains sensitive data, the victim clicks on the link http://example.org/profile.php/noexistening.js. Due to some loose configuration or misconfiguration, the App server receives the requests and pulls the data for page http://example.org/profile.php. 3. Because the content of this page has not yet been cached in the Cache Server (step 6 in Diagram 1), the data will be cached by the cache server due to the extension noexistening.js, which the cache server considers to be a static file. 4. Now the sensitive data of victims under http://example.org/profile.php/noexistening.js. has been cached in the web cache server. 5. The attacker could make a request to http://example.org/profile.php/noexistening.js to pull the data from the web cache server as most of the web cache server has no authentication implemented. | Yes. The attacker has to trigger the victim to visit a crafted link. It will only affect the victims who access the crafted link |
| Cache Poison | Malicious data crafted by an attacker | 1. An attacker identifies and evaluates unkeyed inputs in the HTTP request, mostly headers. 2. An attacker injects a piece of malicious code into the unkeyed inputs and makes a request to the app server 3. The app server extracts data for the malicious request by consuming the malicious codes. 4. The responses with the malicious codes will be rendered to the attacker and the response content will be stored on the web cache server. 5. The victim makes a request to the same page as the attacker and obtains the cached data from the web cache server. The malicious code will be executed at the victim’s end because the cache data contains malicious code. | No. Any users who get data from the compromised cache server. |
According to the table above, certain prerequisites must be met for a successful web cache deception or web cache poisoning.
Prerequisites for web cache deception
- Web cache setting is based on file extension disregarding cache header
- The victim has to to be authenticated when the attacker trigger the victim to access the crafted link.
- Loose or misconfiguration in the application route handler so that web server will return the content https://yourapplication/profile when the users make a request to https://yourapplication/profile/test.js. The following snippet is a simple nodejs application with this kind of misconfiguration.
var express = require("express"),
app = express.createServer();
function fooRoute(req, res, next) {
res.send("YOUR_PROFILE_PAGE");
}
app.get("/profile*", fooRoute);
app.listen(3000);Prerequisites for web cache poison
- An attacker need figure out some unkeyed headers and able to trigger the backend server to return content containing the malicious payload added to these unkeyed headers
- The content with the malicious payload is cached in the cache server and will be distributed to the victims.
How to Prevent Web Cache Deception and Web Cache Poison
It is unlikely that you could ask your engineering team to disable cache altogether. Here are some common mitigation methods that we could prevent these kind of cache issues.
Only Cache Static File
Cache should be strictly applied by truly static files and it should not change based on user input.
Don’t accept Get request with suspicious header
Some web developers are not implement strict validation against HTTP request header as it is really hard for an attacker to modify the HTTP headers of the requests originated by a victim. However, if these vulnerability is used together with web cache, the damage could be devastating. When the web server process a Get request, it should add a validation function to some HTTP headers.



