Shifting to cloud is becoming more prevalent as a cloud based platform could provide operation efficiency, simplicity if the best security practices and proper configuration are enabled when utilizing the cloud vendors. However, sometimes a misconfiguration in utilizing AWS could lead to deadly data breaches.
Common misconfigurations in AWS cloud
In this article, we will break down the 5 most common misconfigurations or ignorance which could lead to a nasty data breach from a pentest perspective.
Misconfiguration 1: Dangling DNS Records lead to Subdomain takeover
If a DNS record entry is pointing to a resource, for example, S3 bucket, IP address, cloudfront instance that are not available and the DNS record is still present in your DNS zone, this is called a “dangling DNS”. A “dangling DNS” in your AWS configuration is likely to lead to subdomain takeover exploitation.
When an attacker finds a dangling DNS, they could create and claim the non-available or non-existent resource and host some malicious content after claiming the non-existent resource (S3 bucket or IP address, etc) . Now when the users are visiting the DNS domain in their browser, their traffic will be directed to the malicious content controlled by the attacker.
Take the following scenarios for a better illustration,
An organization created a DNS record, files.example.org and CNAME to an AWS S3 bucket filessharing_example.s3.amazonaws.com to host some static javascript files
The organization deleted the S3 bucket or the S3 bucket expired and the organization did not renew it. AWS will recycle this S3 bucket name and make it available for other users to claim it.
When the attacker found the DNS record files.example.org is pointing to a nonexist S3 bucket. The attacker could claim the S3 bucket and host some malicious content in this S3 bucket
Now the victims visit files.example.org in its browser, they will be visiting the malicious content controlled by the attackers.
S3 bucket takeover is the most common exploitation when performing penetration test because the exploitation is very straightforward and simple
Mitigations
The mitigation for dangling DNS is easy, to keep robust hygiene practices. When a resource in your AWS is deleted or removed, you need sunset or delete the corresponding DNS record too.
Misconfiguration 2: Internal servers deployed in public subnets
AWS provides a default VPC for a new account. Sometimes, a developer is deploying a server and database directly in the default public subnet of that VPC to speed up the deployment for testing or POC purposes.
Take the following scenarios as an example, a developer was trying to perform a POC to its potential clients. In order to ensure the clients have access to the service, the developers deployed an EC2 instance with the demo into a public network. As a consequence, this could lead to potential data breach if the EC2 instance is hosting an internal application or has the database installed in it.
Mitigation
Deploy internal servers under private subnets and set up the correct security groups to limit the right groups of applications to access it. If the server is a public facing application, ensure that only the necessary ports are running.
Misconfiguration 3: Over permissive S3 bucket
Misconfigured permission of S3 buckets has been identified as the root causes for many data breaches even though AWS set all its buckets and its objects private by default.
Most of these incidents happen when the Resource Based Policies (Bucket Policies) is not correctly configured. In a bucket policy, the owner of the bucket could specify which user has which kind of permissions (read, write,list) to this bucket. A developer or an owner could mistakenly grant permissions to the undesired users.
Take the following publicly disclosed incident for example, the organization is using the following Bucket policy to configure permissions for its S3 bucket
This bucket policy means anyone could read and write any files under the /taskrouter/ directory under this bucket.
Mitigation
Follow the security best practices listed by AWS when configuring your AWS S3 bucket, for example, try to apply least privilege access, enable data encryption, blocking public access to S3 bucket.
Misconfiguration 4: EC2 Metadata Service leaks Secret Token via SSRF
SSRF became a new category of OWASP Top 10 (2021) as it enables attackers to use vulnerable servers to request and receive data from protected internal sources and lead to serious attack. The impact of SSRF is being worsened by the offering of public clouds, like AWS. For example, the most notorious capital one data breach was caused by SSRF exploitation. As a penetration tester, to steal EC2 Metadata with AWS credentials is becoming a standard POC to demonstrate the exploit and damage of the SSRF vulnerabilities.
The following two factors could be blamed for the widespread SSRF attacks against AWS cloud.
2) the service will reveal the IAM credentials of the role attached to the EC2 instances.
Mitigations
Enforcing IMDSv2 to your EC2 instance could significantly reduce the risk of SSRF attack as the IMDSv2 requires a PUT request prioring to extracting the AWS credentials with a get request.
Misconfiguration 5: Private AMIs got shared with public
Accidentally public Amazon Machine Images (AMIs) is another common security issue observed during penetration testing. AWS allows its customers to customize the instance (for example, installing software, configure sensitive environment variables on the instance) and then save it as a custom AMIs.
Once a customized AMI is saved, it could be shared among different accounts or shared with the public. Sometimes, AMI could be shared with the public by mistakes and it leaks to sensitive data leakage if the AMI contains sensitive information.
Conclusion
There are far more misconfigurations that could put your cloud platform in jeopardy. These 5 misconfigurations are the most common misconfigurations in AWS cloud infrastructure from my perspectives when performing penetration testing.
Nevertheless to say, to securely configure a cloud based platform utilizing AWS is a very challenging task as AWS itself is complex and it takes time and effort to understand all the features and options. Sometimes, this is made worse when the recommended configuration or setting is not suitable for your organization or platform.
However, the aforementioned 5 common misconfigurations are not hard to discover when you are following the AWS Security best practices and performing a regular audit against your platform.
Input validation is a widely adopted technique in software development to ensure proper user input data to be processed by the system and prevent malformed data from compromising your system. If a robust input validation method is adopted, input validation can significantly reduce the common web attacks, such as injections and XSS, though it should not be used as the primary method to combat these vulnerabilities.
However, to implement a robust validation method is a very challenging task, you may have to consider many aspects, for example, 1) which input validation method should be used, blacklist, whitelist or regex based 2)when input validation should be performed 3)is the input validation efficient. 4) how to ensure input validation is executed in multiple components in a complicated architecture.
Without a careful consideration of all these areas, your input validation might be flawed and turns out useless to combat malicious user input.
Common mistakes when implementing input validation
Here are some common mistakes observed when performing penetration tests and code reviewing.
Confuse Server Side validation with Client Side Validation
Perform Input Validation before proper decoding
Poor validation Regex leads to ReDOS
Input validation implemented without the context of the entire system
Reinvent the wheel by creating your own input validation method
Blacklist input validation is not comprehensive
Confuse Server Side Validation with Client Side validation
Client Side validation is for user experience/usability, which is more likely to be performed by your browsers during executing some JavaScript code; whereas, server side validation is employed for security control, which is used to ensure proper data is supplied to the server or service. In another word, client side validation does not add any security enhancements to your application.
Nowadays, many web frameworks, for example, Angularjs and react, offer client side input validation to improve user experience and make developers life easier. For example, the following input field will validate whether the user input is a valid email address.
<html><script src=”https://ajax.googleapis.com/ajax/libs/angularjs/1.6.9/angular.min.js”></script> <body ng-app=””> <p>Try writing an E-mail address in the input field:</p> <form name=”myForm”><input type=”email” name=”myInput” ng-model=”myInput”></form>
This build-in client side validation gives a wrong feeling to the developers that input validation has been done by the framework already. As a consequence, Server side validation is not implemented and any attacker could bypass the client input validation and launch a potential attack.
Solutions
Educate your developers and test engineers to understand the difference between client side validation and server side validation so that the correct validation method is implemented.
Perform validation before decoding the input data
As you might be advised when implementing input validation, it should happen as soon as the data is received by the server in order to minimize the risk. That is a true statement and input validation should be executed before the user supplied data is consumed by the server.
When running some bug bounties programs. I found it is very common that the input validation is executed at the wrong time. Sometimes, the input validation is performed before it is converted to the correct format in which the system would consume.
For example, in one test case, an application is vulnerable to XSS vulnerability through a parameter https://evils.com/login?para=vuln_code. An input validation is performed to check whether it contains malicious code, input like javascript:alert(1) or java%09script:alert(1) will be blocked. However, if an attacker changes the payload into Hex format, the input validation method is not able to detect the malicious code.
When input validation is executed, you need to ensure you are validating the user input in the same format in which the System or service would consume. Sometimes, it is necessary to convert and decode the user input before applying input validation functions.
Improper Regex Pattern for validation leads to ReDOS
Many input validations are leveraging regular expressions to define an allowlist for input validations. This is a great way to create allowlist without adding too much restriction on the user input data. However, developing a robust and functional regex is complicated. If not handled properly, it could do more harm than good to your application.
Take the following regex for example, the regex is used to check whether a HTML page is using application/json format JavaScript code for JSON before scraping it by the server.
var regex = /<script type=”application\/json”>((.|\s)*?)<\/script>/;
This regex will lead to ReDOS attack because it contains a so-called “evil regex” pattern ((.|\s)*?) which could introduce backtracking problems.
Here is a POC to demonstrate how long it will take to evaluate the regex when increasing the test string.
var regex = /<script type=”application\/json”>((.|\s)*?)<\/script>/; for(var i = 1; i <= 500; i++) { var time = Date.now(); var payload = “<script type=\”application/json\”>”+” “.repeat(i)+”test”; payload.match(regex) var time_cost = Date.now() – time; console.log(payload); console.log(“Trim time : ” + payload.length + “: ” + time_cost+” ms”); }
To create a very robust regex is hard, but here are some common method you might follow
Set the length limitation if possible
Set a time t limitation for the regex matching. If the regex matching is taking too long than expect, just kill the process
Optimize your regex with Atomic grouping to prevent endless backtracking.
Input validation without clear context of the entire system
With more and more businesses adopting microservices, the micro-services architecture sometimes could bring challenges for input validation functions. When data flows between multiple microservice, the input validation implemented for microservice A might not be sufficient for microservice B; or input validation is not implemented for all the microservices due to lack of centralized input validation functions.
In order to illustrate this common mistake better, I would like to use the following typical AWS microservice diagram as an example.
Here are two scenarios where input validations could go wrong
Scenario 1 Input validations not implemented for all microservice
In some scenarios, there might be multiple services behind the API Gateway to consume the user input data. Some services might have to give response to the user input directly, for example, Service B in the above diagram; whereas, some microservice are designed to handle some background jobs, for example, Service A and Service C.
Since service A and service C are implemented for some background jobs and they do not respond to the user input directly, the developers might ignore implementing input validation for these two services if a centralized input validation is not enforced for this microservice architecture. As a consequence, lack of input validation in service A and Service C could lead to exploitation.
Scenario 2 Input validation for one service is insufficient for its downstream services.
In this scenario, input validation is implemented for microservice B and it is sufficient for microservice B to block malicious user input. However, the input validation might not be sufficient for its downstream Service D.
A good example could be found under my previous blog post Steal restricted sensitive data with template language The microservice B is validating whether user input is a valid template. The input validation implemented in microservice B is robust for this service. However, when service D is compiling the user input template validated by microservice B with some data to get the final output, the process could lead to data leakage because microservice D is not validating the compiled template.
Solutions
Before implementing the user input validations, the developers and security engineers should obtain a comprehensive understanding of the entire system and ensure input validation should be applied in all the components/microservices.
“Reinvent the wheel” by creating your own input validation methods
Another common mistake that I observed when performing code reviewing, is that many engineers are creating their own input validation methods though there are very matured input validation libraries used by other organizations. For example, if you need to validate whether the input is an email address or the input is a valid credit card number, you have many options to choose from matured input validation libraries. Creating your own validation method is time consuming and it could be defective without robust tests.
Solution
To avoid “Reinvent the wheel”, you need to figure out the purpose of your input validation and try to search whether there are existing validations already implemented. If there are some popular libraries you could use, try to use the existing libraries instead of creating new ones.
Blacklist is not comprehensive
One of the most popular quotes you are seeing frequently is “You could not control things that you could not measure”. This quote could explain the pain of using the blacklist method for user input validation.
Blacklist approach in Input validation is to define which kind of user inputs should be blocked. With that said, developers and security engineers need to understand what inputs are considered “bad” and should be blocked by the blacklist. The efficiency of the blacklist method is largely dependent on the knowledge of the developers and their expectation of bad user inputs.
However, security incidents or breaches are most likely to occur when malicious users are injecting something unexpected.
Solution
In many cases, blacklisting and whitelisting are implemented together to meet the requirement. If possible, try to employ both methods to combat malicious user inputs.
Conclusion
It could not be overemphasized how import input validation could be used to help your organization to combat malicious attacks. Without a robust input validation method in your service or system, you are likely to open the door for potential security incidents.
It could be super easy to start implementing input validations in your service, but you really need to pay attention to these common mistakes found in many validation methods. Try to understand your system or service, choose the right validation methods suitable for your organization, once decided try to perform a thorough testing against your method.
Back to Nov, 2020, I got the chance to evaluate Github Code Scanning, mainly CodeQL, as part of our effort to improve the security posture of our source code right after Github announced Code scanning became available in Sep 2020. I selected 4 different services written with Java, Python, C++ and JavaScript respectively and ran CodeQL scanning against them. Though there were some great advantages when it comes to ease of use and collaboration, the overall CodeQL code scanning results were average compared to other traditional commercial SAST tools. The result was not good enough for our team to replace the existing SAST tools.
Recently, our team started to assess Github Advance Security (GHAS) again to understand whether we could use Github Advanced Security Feature as a unified platform to secure our source code by evaluating the three main features Code Scanning, Secret Scanning and Dependency vulnerability in the GHAS. The overall evaluation totally surpassed my expectation as I saw a significant improvement of Github Advanced Security features by comparing with the results of evaluation conducted one and half years ago.
In this post, I would like to share and highlight some valuable findings and features the GHAS surprised me with and how they could help your organization to secure its codes and build secure services.
How did we start the re-evaluation?
Before we got involved with Github Advanced Security, we were clear that what we really wanted was a unified platform that could perform code scanning (SAST), secret detection, software composition analysis (3rd party dependency vulnerability) and it should be easily integrated into our current CI pipelines.
With the previous evaluation and experience with Github Code Scanning, we figured out that GHAS could be a one stop solution to meet all the requirements. However, due to the previous evaluation, I was really concerned about the Code Scanning performance before we started evaluation. Well, it turns out that the concern was over worried.
In order to conduct a thorough evaluation, we selected 15 services/repo to cover all languages supported by Github to evaluate the GHAS , diagnose the findings and compare them with the existing tools that we have deployed.
How did GHAS outperform others
With the completion of the GHAS evaluation, the following are some highlights we think that the GHAS are outperforming others tools.
1.Code Scanning: Excellent Auto Build with Flexible Configuration
Nevertheless to say, Code scanning is a resource consuming task. Some of the repos that I am evaluating are monolithic repos, so building and scanning them are time and resource consuming. When scanning one of this monolithic repo with a popular open source tool we were evaluating, my personal laptop got completely frozen after running the scan for 10 minutes as the scanning task was consuming more than 9G memories.
However, with Github Code Scanning (we only enabled CodeQL scanning by default), we found that this is not an issue because it provides an excellent auto build and scanning process in Github-hosted runners deployed in the Github network.
If you could use Github-hosted runner to build and scan the service, you don’t have to bother your IT team to set up a self-hosted runner either with your own laptop or a remote server in your network. We were able to use the Github-hosted runner to build and launch the scan against 14 repos out of 15 selected. That means more than 93% percent of the scans could be completed with Github-hosted runners. That is a significant advantage as a high successful rate of using Github-Hosted runners means less resources required from our organization to build and maintain a self-hosted server to run the scans.
Flexible Configuration to add manual build commands
Some of the codes in the select repos have a non-standard build process. We could NOT simply run the default maven buildorcmake commands provided by the Auto-Build function. Under this situation, the flexibility to add the manual build commands is really necessary and powerful to ensure a successful build process . For example, we were able to build our Java service by adding some customized configuration for the maven setting with the help of defining manual build commands in the yaml configuration file.
Github Secret to keep your build information safe
As mentioned above, we have to set up some environment variables in the build process. These environment variables are very sensitive and they should not be exposed in the CodeQL yaml configuration files directly. The Github secrets function lets us hide the sensitive secrets in the yaml configuration file.
2. Code Scanning: Less False Positive with high true positive rate
One of the biggest challenges in SAST tool/Code scanning is that it likely yields a high number of False Positives, which costs tons of time and effort for the engineering team to validate these false findings. The main reason for the high number of false positives is that static code analysis is largely based on assumptions and modeling methods after it builds the call stack (from source to sink), which is different from the DAST tool where the test payloads are actually executed by application codes.
As weeding out false positives is time and resource intensive, low False Positive rate and high true positive rate are the key factors for the entire evaluation. During the evaluation, we went through all the critical, high, medium vulnerabilities reported byCodeQL. Here are some key findings
Less False Positives than we expected
For the projects writing in Java, C++ and C#, the false positives are really low. The best one is with the Java languages, we saw a false positive rate at 0% with 2 valid findings. We double check it with another popular open source tool, the performance is equivalent where 2 valid findings were reported. Overall, for the compiled languages, most of the SAST tools we compared have a low false positive rate.
CodeQL stands out when it comes to the Script languages, for example, JavaScript and Ruby. In general, Github CodeQL has less False Positive rate reported in scripting language. For example, CodeQL has false positive rates at 44% compared to 62% false positives rates when scanning a repo written in script language.
Relatively high True Positive rates
A good false positive rate does not guarantee the tool is a good one. A SAST tool could produce a 0% false positive rate with zero vulnerability detection. When analyzing the CodeQL scanning results, we calculated that the True Positive detection rate is higher compared to other tools for most of the repos. For example, CodeQL scan reported 25 valid findings against 22 in one repo, and 5 versus 3 findings in another repo when comparing the results generated from one popular SAST tool.
Note: Some reported vulnerabilities are vulnerable but not really exploitable or reachable, under these scenarios, most of these types of vulnerabilities are categorized as False Positives.
3. Code Scanning: some vulnerability detections are intelligent
Most of the Code analysis SAST tools are using a set of rules to detect potential vulnerability when scanning the code. Github CodeQL is NOT an exception. It is utilizing a set of predefined rules to detect the vulnerabilities. Due to that, many security engineers and developers thinks SAST is just a dumb tool to perform a matching between the code and the rule set in order to detect a vulnerability. That argument is kind of true to a large extent.
However, we found that some vulnerability reported by CodeQL seems to be intelligent and these detections were only reported by CodeQL scanning. Here are a couple of examples based on some real detection we found
Inefficient regular expression detection
This detection is to check whether your regex pattern is potentially vulnerable to ReDOS attack. For example, CodeQL is reporting the Inefficient regular expression vulnerability against the following code in an open source library.
This is a true security issue, which has been ignored by other tools. An attacker could dramatically slow down the performance of a server with a malicious string less than 100 characters. You could find a detailed post in another post.
Incomplete URL substring sanitization detection
Here is an example where Incomplete URL substring sanitization vulnerability is detected
These detection looks simple but also intelligent from my perspective. There are many more other smart detections we found with CodeQL, I chose these two on purpose because I found these kinds of vulnerabilities are prevailing in many public Github repos when performing a brief code scanning against a tiny portion of open source repos.
4. Code Scanning: Easy to track the origin of the vulnerable code
This unique advantage makes the entire triaging process much easier and quicker as we could simply use the git blame function to track down which engineers committed the vulnerable code, what the vulnerable codes are supposed to accomplish and the corresponding Jira ticket to these changes.
After collecting all the related information of the vulnerable findings, we could tell the potential impact of the vulnerability, the potential remediation method and how quickly we could fix it.
5. Code Scanning: multiple languages support in one scan
Coverage is another factor when evaluating a code analysis SAST tool. Many SAST tools ask you to predefine the language before running the scans as it could only scan one language at a time. Whereas, CodeQL allows you to specify multiple languages and scan them in one scan without requiring some predefined settings.
Even for compiled languages, you could specify multiple builds for different languages in one scan. It is a really useful feature if you have some monolithic repos written with different languages and you want to cover all the code in the repo.
6. Secret Scanning: a powerful feature worthy a try
Secret Scanning is another feature we evaluate partly and we think it is a feature worthy of mention as there are some unique and true values when using it properly.
Scan your entire Git history on all presented branches
Github Secret scanning will scan your entire Git history on all branches present in your Github repos to find potential secrets exposed in your code bases. That is a huge difference compared with other tools, where the scan is performed against the main remote branch or local branch when scan is performed locally
Some developers might accidently add secrets into the code when pushing the changes to the remote branch. This could be prevented by enabling push protection, which allows Github to reject the push when the secret scanning finds any suspected secrets.
7. Code Scanning: clear-text logging of sensitive data detection, a hidden gem
Insecure logging could cause a security breach or incident in many cases. I shared some thoughts in one of my blog posts. When analyzing all the code scanning results, It was refreshing to realize that CodeQL has a detection function to check whether sensitive data is added into log files.
I believe this detection has great values which are mostly underestimated by many SAST tools. From my experience as a security engineer and a penetration test, I found it is so common for engineers to add sensitive data into the log file for debug purposes, but they eventually forget to remove it before the changs deployed into production. As a consequence, they are collecting some sensitive data from customers by accident.
With the help of this detection method, many logging issues could be detected before the code is pushed into a production environment.
Limitations in Github Advanced Security (GHAS)
Definitely, I could list more bright sides of how CodeQL is outperforming other tools. But I think it is important to remind people that GHAS, as a newly emerged and growing security tool, has some limitations as many other security tools do.
Here are some limitations that we could summarize from our evaluation.
Limitation 1: Insufficient disk space in Github-hosted runner to build large projects
We were able to use Github-hosted runner to build 14 services out of 15 select repositories. We had issues building one large project using Github-hosted runner as the build was hitting `not enough space on the disk` error all the time no matter how we customize the build commands. After some analysis, we found the disk space allocated for the Github-hosted runner is really limited for the Windows runners.
Suggestion: At this moment, there are two types of windows runner supported by Github, windows-2022 and windows-2019. If the Github team could assign specific roles for these two types of windows runner, it might be helpful to resolve the issue. For example, window-2022 should ONLY be used to build Dotnet projects with only Dotnet environment setup in this VM, whereas,window-2019 could be used for other types of build environments.
Limitation 2: Certain frameworks are not supported in CodeQ
Though the code analysis tool CodeQL supports a large range of frameworks, certain frameworks are not well supported at the moment of the evaluation. For example, Ruby on Rails framework was not supported currently in the CodeQL and we saw some false negatives due to the lack of support for this framework.
Limitation 3: Some False Positives could be filtered out
Some vulnerabilities reported by CodeQL are vulnerable, but the vulnerable piece of code will not be executed in any case because there are multiple validation or whitelisting methods applied before a user supplied input value to reach the vulnerable code. I believe this kind of filtering could be filtered out by tuning the detection method.
Limitation 4: Current dependency vulnerability detection is too loose
In my opinion, the software composition analysis (3rd party dependency vulnerability) feature in GHAS is too loose because it mainly scans the package management files, like, pom.xml, package.json files to 1)extract the package name and version. 2)Identify the vulnerability based on the version number. It means, Github Dependabot will flag a vulnerability in your code even if you are not calling the vulnerable functions in the vulnerable dependency library.
It seems that the Github team is implementing some changes to check whether your codes are actually calling the vulnerable function rather than based on version number. Once this is fully rolled out, I believe that it will bring the dependency vulnerability detection to a totally new level.
Conclusion
Though Github Advance Security is a relatively new player in the security market, I could say that the code analysis tool CodeQL could compete with any other SAST tools in the market that I have evaluated so far. With two separate evaluation experiences against GHAS, I observed such a huge improvement of scanning quality and new features adopted in it just in one and half years. That really surprises me and makes me believe the GHAS will be adopted by more and more organizations with the quality of detection and the speed or renovation in the tools.
Github Advance Security (GHAS) is not a silver bullet to catch all the issues by scanning in the code base as it has its own limitations, but this tool is clearly the best of the SAST tools that I have evaluated.
Regardless of which positions you are fulfilling in the development lifecycle in your organization, regular expressions are useful tools to make your work more efficient. While writing a basic regex itself might not be very hard, defining a robust and secure one could be a real challenge.
You may start to ponder that I remembered that some security incidents were caused by an insufficient regex pattern where a malicious user input was NOT blocked or detected by the regex. You are right in that perspective and this is a very common scenarios of poor regex leading to a security incident. But in this article, I would like to talk about the danger of poorly designed regexes from a different perspective, ReDOS, which is an overlooked security issue by many developers and security engineers in my opinion.
ReDOS, an overlooked security risk
Before we start the exploration of ReDOS, we need to understand two basic things 1) Regular expression is a sequence of characters that specifies a search pattern in text, which are commonly used by string-searching algorithms 2) when the regex matching (string searching) is performed, the behind scene algorithm is using a so called backtracking algorithm, where it is a brute forcing method to find a solution/path in a context that will match with the regex, it means there could be an infinite loop when a regex matching is performed behind the scene. That is the root cause of the DOS caused by regular expression, ReDOS, for short.
Though the severity of ReDOS could be critical as it could paralyze your web server just with a single malformed string, this vulnerability is always overlooked by many security engineers because 1)they are not able to identify a regex with potential ReDOS vulnerability 2) ignore or underestimate the risk of it 3)not able to craft a malicious string to demonstrate the exploitation of this vulnerabilities. As a security engineer, I was trying to downplay the severity of the ReDOS vulnerability as well as I was not persuaded to believe one single string would be able to totally freeze a web server. I started to change my mind after I was able to exploit a ReDOS vulnerability imposed by an inefficient regex with an elaborate string. During the exploitation, the elaborate string consumed 100% CPU of the server when a regex match is performed between the string (payload) and regex
How did I start?
When I was performing a static code analysis against a piece of code with some help of a SAST tool, a vulnerability was flagged against the following regex and it states the following piece of regex could lead to ReDOS attack. (Note: The regex was modified and changed to make the POC easier to follow)
var regex = /\A([\sa-z!#]|\w#\w|[\s\w]+\”)*\z/g
After reviewing the regex, I started to craft a string by using an online tool https://regex101.com/ to match the regex. It did not take me long to find out that the regex101 is reporting Catastrophic backtracking error when evaluating the following string.
That error message clearly shows the regex has a flaw in it. I was then using the Debugger functions provided by Regex101 to validate how the backtrack steps are created. After running the debugger, it indicated that there are some group repetitions in the regex, which makes the backtracking into an endless loop.
After figuring out a possible ReDOS vulnerability could be exploited, I created the following POC codes and ran it on a free tier AWS EC2 t2.micro instance (1G RAM).
The CPU usage of the EC2 instance hiked to 100% after the length of the test payload reached 99 characters after running the POC code, which really surprised me.
The above POC definitely changed my understanding of the ReDOS vulnerability as the impact could be catastrophic. You might start to ask yourself about how to spot this kind of vulnerability in your code and eliminate it before it gets exploited.
Identify DeROS vulnerabilities in you codes
It is relatively complicated to justify whether your regex is vulnerable to ReDOS. However, there are a couple of approaches that could make it a little bit easier for you.
Use some patterns to evaluate your Regex
Suggested by OWASP, there are so called pattern to identify evil regex
Grouping with repetition
Inside the repeated group:
Repetition
Alternation with overlapping
When you find a regex with repetition patterns, for example, + character is used in your regex, you should start to pay some attention to the regex as it contains repetition patterns.
Use some automation tool
There are also some automation tools that you might be able to use, for example, rxxr2 and ReScue are some open source tools you could use neatly. If you have your source code hosted in Github and have Github Advance Security enabled, you could scan your code with CodeQL and the vulnerable regex could be flagged as well though you still need to verify it manually.
Conclusion
Composing an efficient and robust regex is hard and to spot a regex vulnerable to ReDOS is not easier either. This article just attempts to explore the basic problems of ReDOS and how to identify and exploit it with the help of some tools by providing a concrete example.
As stated in the before ahead, most developers, even the security engineers are not really aware of the potential risks of an efficient regex. The best way to avoid the ReDOS risk caused by an inefficient regex is to inform your developers and security engineers about the danger of the ReDOS and perform a thorough code review and testing when a regex has to be used in your code.
This blog will demonstrate how a hacker could harvest credentials of the main application of an organization by taking advantage of the autofill features implemented in modern browsers and password manager tools and bypassing the CSP restrictions.
Overall Structure of the Organization
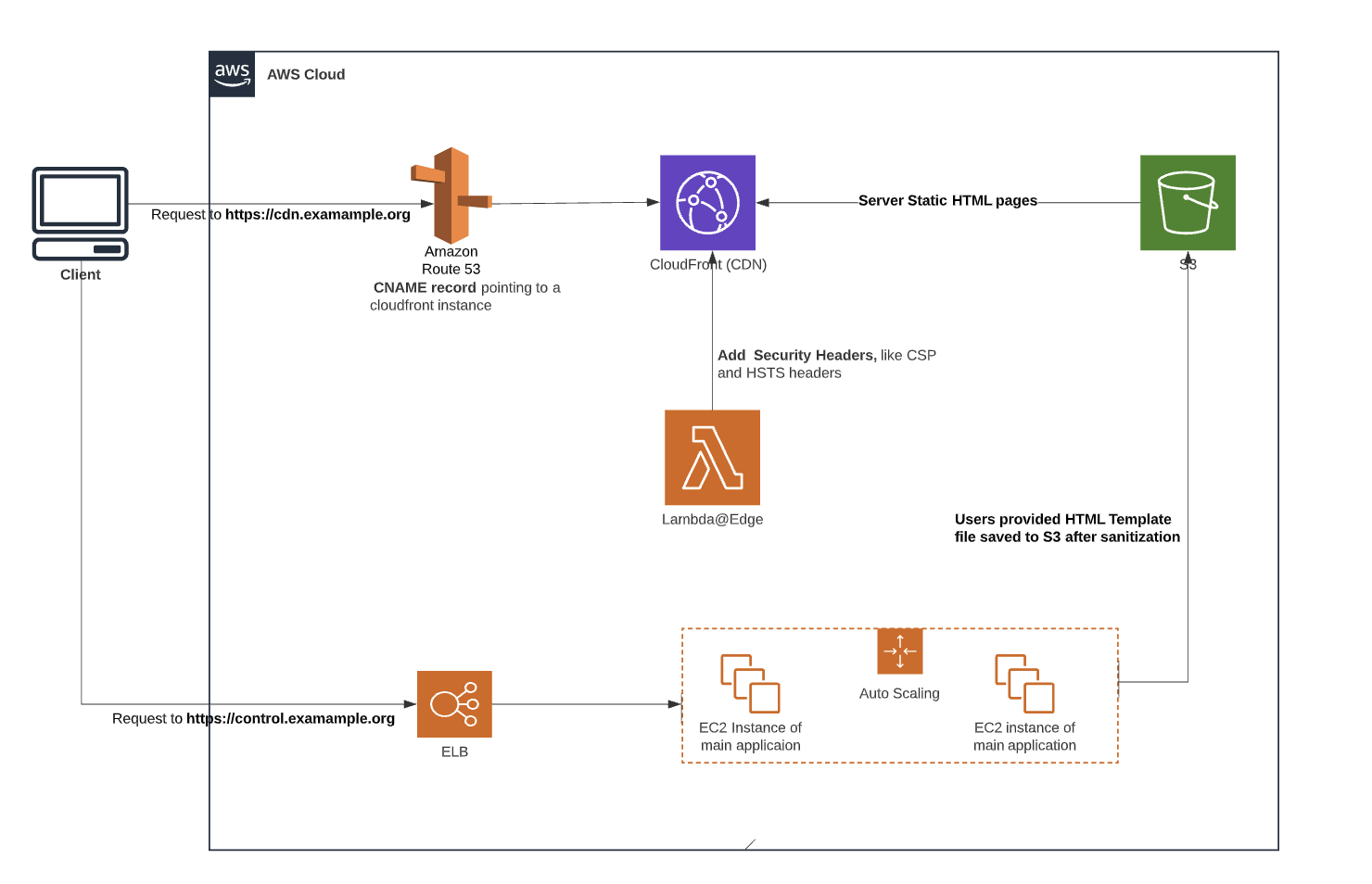
The organization has two main applications, the first one https://control.example.org, which is the main application acting as a central dashboard for its customers. One feature under this application allows its customers to upload sanitized HTML files as a template into a S3 bucket . The S3 bucket is behind AWS CloudFront and the CloudFront is CNAME to cdn.example.org for performance and scalability reasons.
The following diagrams illustrate how these two applications work.
XSS exploitation is not possible due to sanitization and CSP header
As the application allows users supplied HTML template through the control panel https://control.example.org and then render it under the https://cdn.exampe.com/my_user_id/template1, the first thought was to check whether XSS is possible. However, after spending some time on discovering potential XSS vulnerabilities and exploiting them, it turns out this method did not work as expected due to the following implementation to prevent XSS exploitation.
User input Sanitization Implemented under control.example.org
The user input sanitization seems to be very robust after numerous with different payloads. It seems that only these DOM elements <div >,<form>, <input>,<image> and <a> are allowed to be added in the user’s supplied HTML template whereas all the event handlers are filtered out.
The following template seems to be able to pass the sanitization method and is able to be stored and rendered under the browser when opening https://cdn.exampe.com/{user_id}/template1
However, the Content-Security-Policy header implemented under cdn.example.org is blocking the execution of these JavaScripts.
Strict Content-Security-Policy is present under cdn.example.org
The cdn.example.org where users supplied HTML template has the below Content-Security-Policy added by AWS Lambda@Edge in order to prevent potential XSS exploitation
Since the Content-Security-Policy does not allow inline JavaScript when rendering the page under a modern browser, the template containing inline JavaScript uploaded could not be used to launch XSS exploitation.
Even though launching XSS exploitation seems not feasible at this moment due to the restrictions, we could explore other potential exploitation methods.
Take advantage of autofill feature to steal user credentials
Most modern browsers and password managers have Autofill features enabled by default to bring a faster sign in, billing information and other user experiences. It means, the browser or password managers will save these user inputs and populate them and autofill them next time for you.
The feature is convenient but with a tradeoff for security. There are a couple of cavities in the feature. One big problem is that the Autofill feature will pull saved credentials from its sibling subdomains and autofill them into forms located under other subdomains.
For example, users login to the https://control.example.org and click Save passwords pop ups in the browser during login. The saved username/password will be pulled from the browsers and autofill into the Login form again next time when users open the login page under https://control.example.org.
Now, users created a similar Login Form (same names for the input fields) on a sibling subdomain https://cdn.example.org, the browser will pull the save password for control.example.com and autofill it under the Login form under https://cdn.example.org. That sounds quite scary if an attacker could control another subdomain or is able to manipulate some pages in the subdomains.
From an attacker’s perspective, once the username and password are auto filled into a Login Form they control, they could steal these credentials by modifying the action attribute in the Login form to receive the credentials once users click the Signin button if auto submit is not enabled.
You make it an even converter by applying a Clickjacking exploiting where your trigger user clicks the Signin button.
Conclusion
Autofill feature provided by password managers and browsers is a convenient feature with security tradeoff. Especially, when your website has potential XSS vulnerabilities or there are many subdomains under your organization, you need to pay extra attention to manage the subdomains. For end users, if possible you could turn off autofill password features to prevent password stealing.
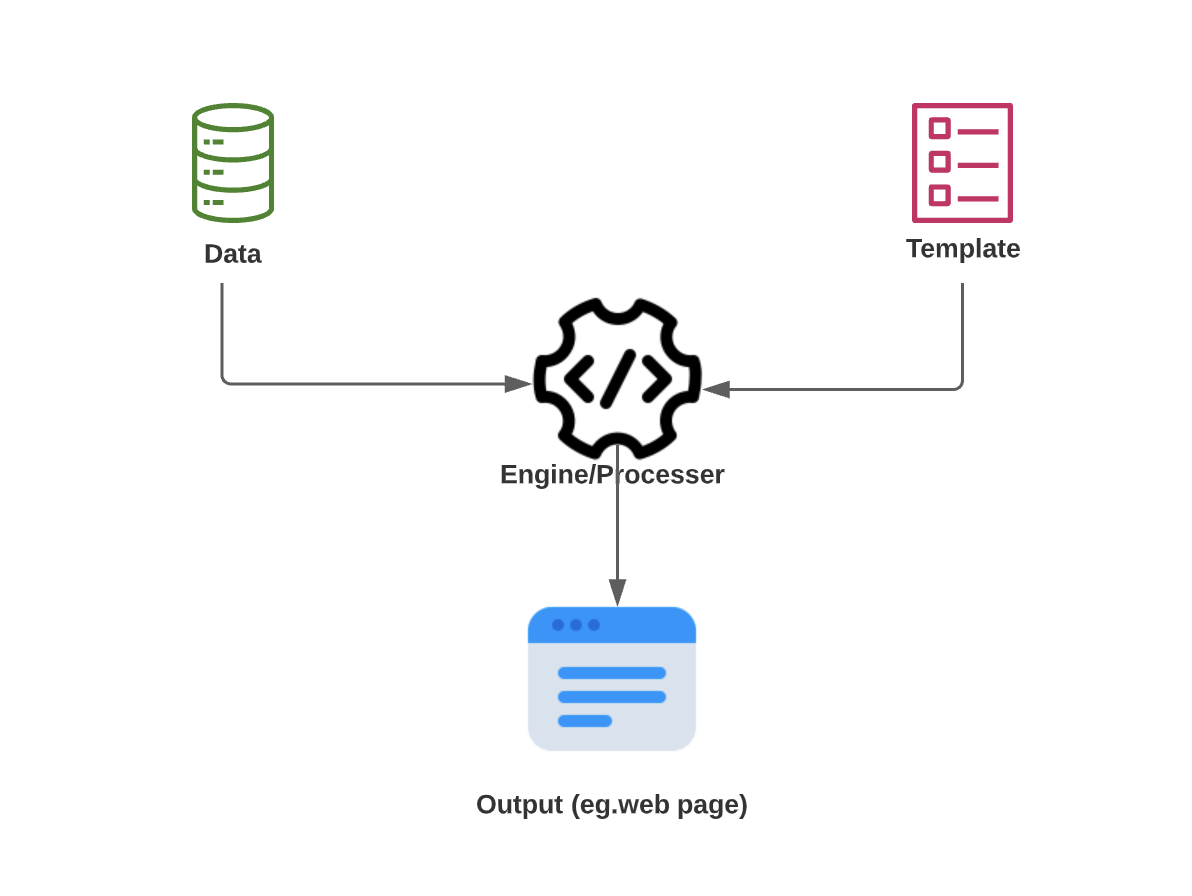
Template language is a language which allows developers defining placeholders that should later on be inserted or replaced with some dynamic data (variables). As it indicates from the definition, the main usage of template language is to give more flexibility to allow developers to insert some dynamic data into a predefined template. The dynamic data could be generated from a different server or a new service based on the condition of existing sessions or use cases. There are numerous templating languages widely used in web developments. Among them, Handlebars, EJS, Django, Mustache and Freemarker are very popular ones. The three main components when using a template language are , dynamic data(variables), template and the template engine to compile the data and template.
How Template Language works
As template languages provide more flexibility for web developments, it also introduces some security issues due to it. Clearly SSTI is the most notorious vulnerability discovered among various template languages.
Security Concerns beyond SSTI with Template Languages
SSTI vulnerabilities could be avoid
Server Side Template Injections (SSTI) issues are the most common vulnerabilities discovered among many different languages. Server-side template injection is when an attacker is able to use native template syntax to inject a malicious payload into a template, which is then executed on server-side when the template engine/processor processes the user supplied template. A list of vulnerable template languages and its exploitation injection code could be found here and it is quite comprehensive to understand.
Most of SSTI exploitation leads to arbitrary code execution and server compromise. Due to that, many template languages deploy default Sandbox and Sanitization features to prevent the template engine from accessing risky modules by disabling them in default settings. It means, when a user-provided template or data is processed by the engine, it can not access these risky modules even though the malicious template contains a call to the risky modules. For example, HandleBars introduced a new restriction to forbidden access prototype properties and methods of the context object by default since 4.6.0 to mitigate the code execution caused by server side template injections. Some applications using template language are also deploying a very strict sanitization method to disallow certain characters or regexes to prevent other vulnerabilities caused by SSTI, such as adding sanitize function against the final output to prevent XSS issues.
Even though a strong Sandbox added by the template language itself and a robust sanitization method is deployed on the top of it to ensure the template could not be abused by SSTI attack , your applications could be still at risk due to improper configuration of how dynamic data could be consumed by the template engine.
Data leakage still occurs when template engines could process data out of the permitted scope.
Take the following instance as an example.
Under one application, an Admin user could create an organization and make sensitive operations through Dashboard or performing API requests. Once an organization is created, the Admin could add multiple users with limited permission to the Organization settings. A user could invite new users to join the organization by sending them an invitation email. To make the email more dynamic and allow the users to modify the email template, it is using a template language to compile the email template.
Under a standard operation, a user could send an email to invite a new user by taking the following steps.
Step 1: A user could create the following email template from the dashboard and use it to send email to a new user.
<h2>Dear Friends </h2> <div> <p> Please join {{ organization.name }} to share your fun moments by clicking the invitation link {{organization.invitation_link}}. Your friends are waiting for you <p> <p>Best {{ user.name }}</p> <div>
Step 2: Application will process the email template with the template language engine once the user saves the template.
The application server will a) validate whether there are potential template injection threats by using both the sanitization and sandbox method b)If the template is safe and syntax is correct, replace the placeholders like {{ organizatioin.name }}, {{ user. name }} with the dynamic data extracted from the server. For example, the App Server could query the DB and get the current Organization and user data from DB and present it with a JSON object format.
Step 3: The invitation email will be sent to another user with the final output.
Once the template engine replaces all the placeholders in the email template with the dynamic data to generate the final email output, an email will be sent to the invited user.
Supposed that security control implemented on the server side is robust enough to prevent Server Side Template Injection attack by its sanitization and sandbox method, But it could still leave an open security hole due to lack of access control of dynamic data and insufficient validation when consuming the dynamic data.
Under this case, the organization data pulled from the application server contains more data than the user is permitted to access, for example, the api_key andapi_private_token which should NOT be accessible by a team user in a normal workflow. A non-admin user has no way to extract this sensitive data.
However, a user now could access them by crafting a deliberate template to steal them even without triggering any violations. If the user is using the following crafted template, the organization api_key and api_private_token will be disclosed to them when sending out an inviting email using this template.
<h2>Dear Friends </h2> <div> <p> Please join {{ organization.name }} to share your fun moments by clicking the invitation link {{organization.invitation_link}}. Your friends are waiting for you. <p> <p>Best {{ user.name }}</p> {{organization.api_key}} {{ogranization.api_private_token}} <div>
Why does the template engine access more data than the users permitted?
There are various reasons why the server provides more data out of the user’s permission scope to the template engine when processing the template. Here are three common reasons by referring to a couple of real scenarios that I experienced.
Reason 1: Sanitization and sandbox method is only applied to check SSTI attacks patterns.
If the user supplied template is NOT violating certain rules defined to match SSTI attack pattern, the server template engine will proceed the replacement action without validating whether the template is attempting to consume the data beyond its designed scope.
Reason 2: Insufficient integration testing between micro services
It is very common for a company to have different teams for frontend and backend service development. The Frontend team will be in charge of providing an interface for users to define a template and validate the user supplied template . Whereas, the backend team will provide the functions to extract the dynamic data to replace the template once the frontend passes a validated template to the backend. Both teams seem to perform their responsibility correctly, however, the frontend is blind to what kind of dynamic data the backend service provides and the backend has no way to validate which kind of data is allowed to be consumed by the frontend without a good suite of integration tests.
Reason 3: Access Control is not implemented in internal micro services
In a micro service development environment, I have seen many times that no access controls are deployed in the internal micro services. Once the request passes the access control implemented in the public services, the internal micro service is not going to perform another layer of validation when the public service calls the internal service. In this case, the internal service that pulls the organization data from the DB does not validate whether the user has the permission to access certain fields.
How to prevent data leakage from abusing Template Language
To avoid data leakage caused by taking advantage of the template language, various means are available for developers to adopt during the development phase.
Use a whitelist of dynamic data (variables in the template, {{ }}) rather than blacklist if a whitelist method is possible when validating the user supplied template
Perform the sanitization and validation after the user supplied template is compiled by the template engine to check whether there is potential sensitive data after the compilation..
Add access control and permission validation between services. If service A is going to consume data from service B, perform a permission check to ensure the user calling service A has the right permission to consume all the data provided by service B.
Besides adopting strict rules when processing template language during the development phase, a comprehensive and thorough test is vital to catch some overlooked areas.
Conclusion
While enjoying the flexibility provided by Template Language, developers and security teams should bear in mind that more flexibility also provides more attacking surface for malicious users. The SSTI issue is not the only security issue that you should be aware of, you need to pay attention to the potential date leakage caused by insufficient sanitization or lack of access control to sensitive data. It means, your sanitization pattern should not only match potential SSTI attack patterns , but sensitive data patterns as well.
If you are part of a security team, it is very likely that your team has been feverishly remediating the vulnerabilities caused by log4j in the past two months. It is really frustrating and struggling as the potential damage of this vulnerability could be catastrophic if exploited. However, the slimy bright side of it , at least, means that your developer team is trying to implement logging functions in the product for monitoring or debugging purposes.
However, logging itself sometimes could be another security issue that is often overlooked as many developers are treating logging as an internal debugging and monitoring functions where security enforcement is often missing. I have observed many cases where improper logging functions turn out to be security incidents and add many burdens to its security team to overturn the damage.
Apply logging functions with security controls
Before we dive deep into the details, let us look at the following piece of code from an old internal project that I created a while back. If you are using NodeJs Express framework, you could pinpoint that this piece of code is acting as a middleware to log every single HTTP request with the request body into a log file
The above piece of code definitely composes security issues if you start to review it from security perspective. First of all, sensitive information in the HTTP request could be added to logs files and it could potentially cause a data leakage if the logs files are accessed by unauthorized users. The internal project is a web application with a login and registration function. As consequence of the above logging functions, the registration verification token and the username and password in the HTTP requestes could be leaked into the log files.
Potential Risks Caused by Logging
Risk 1: Sensitive Data are logged in log files
Logging sensitive data without proper masking or filtering methods is a common security ignorance from startup to enterprise due to many reasons. Couple of years back, twitter sent out an announcement for its users and urged them to change passwords due to unmasked/unfiltered passwords being logged into an internal log file.
Reason 1: Security is not baked into entire SDLC
Many development organizations are involved their security teams at the test phase of the software/service development cycles. Without consulting the security team at design and development phase, many developers are not aware which data should be masked or filtered before implementing the log functions.
One tricky and representative example that I have experienced was that the development teams got a list of blacklist data entries, like IP, password and token by referring to a document created from the security team a while back. They applied the filtering method into the log function without consulting with the Security team. However, the ‘referer’ header containing sensitive API tokens from customers was logged into the log files as it was not included in the predefined black list. This implementation mistake was discovered after the feature has been shipped into production environment and it took a while to purge the sensitive data from the log systems.
Reason 2: Lack of standard logging functions in a complex environment
With more and more companies adopting the micro service architecture and making the development environment complex, lack of standard log functions could be another reason where sensitive data is logged and exposed into log files.
The following diagram is a typical workflow of micro service architecture, where the API gateway is exposed to the public to handle API requests and many micro servers are deployed in its private VPC to process the API requests. Some developers are probably aware that sensitive data must be filtered out at the API gateway level before sending it to the S3 log system. However, when the requests passed are handled in the internal micro service (for example, micro service B), the developers might forget to perform the filtering as they believe the service is residing in the internal VPC and there is no need to filter sensitive data before writing to the log files. As a result of that, potential sensitive data could be logged in to the log file by some internal micro services.
Reason 3: Insufficient QA and Security Testing
It is common some QA are only performing blackbox testing whereas Security Team are only employing some automation scanning tools to scan the applications to find the potential flaw in the codes. Then it is very difficult for the QA team and security team to figure out the security issues caused by logging without manual code reviewing.
Risk 2: Malicious Data are process and logged without validation
Another risk when implementing logging functions and writing data to log is that maliciou data is processed and executed without any validation. You might be curious about why I should perform certain validation when processing the log data and storing it in a log file as the entire purpose of logging is to capture the raw data and use it for analysis.
The reason is that you might be at risk of Deserialization exploitation when validation is absent from your logging functions. I have seen many developers dumping the entire object into the log file in some cases. When this happens, they are very likely to use some serialization functions to serialize the object and write it to the log file. After that, they may deserialize the logged data for analyzing purposes. In this case, it is possible that you are at risk of deserialization exploitation.
Take the Log4j as an example, except the Log4jShell vulnerability, it has been suffering from a couple of deserialization vulnerabilities where untrusted log data could lead to remote code execuations.
Some Best Practices
To ensure your logging function is not becoming a burden for your security and even turned against you when it leads to a security incident. Some best practices could be followed.
Involve Security at every phase of SDLC when implement log function
Security applies at every phase of the software development life cycle (SDLC). If you don’t have a security review procedure set up in your organization, it is time for you to define it now. By designing a secure log function or log management feature by collaborating with your security team would save your organization much more time and effort. For example, the security team might ask you to avoid using GET instead of POST if your logging function is going to log all the requests in the log. They could also ask you to mask certain sensitive data as soon as the data is processed before it gets logged in to the log files.
Implement a standard and centralized logging function
When the organization is getting larger and larger, your platform and service is getting more sophisticated. Without a standard or centralized logging function, each team is forced to choose its own way to implement logging functions in the service they are in charge of. This could add many security uncertainties in the log functions as you could not foreseen how the logging function is implemented
Consistent monitoring and scan your log data
Sometimes, unexpected data could still be logged into the log file even though you have set up strict logging functions to mask or filter all the sensitive data. For example, your clients might not follow your API usage guidance and send sensitive data when calling your API endpoints. Your log function might log these sensitive data into the log files as the usage of the API is not intended as it was designed. Under this case, you need to have a monitoring tool to scan your log data to check whether there is unexpected sensitive data logging into the log files.
Understand that data you are logging
“If you could not measure it, you could not manage it”. It also applies to security. If you don’t know which kind of data you are logging, you could not really secure it. For example, if you are going to dump an entire object into your log file by calling some serialization functions without validation the object data, you are likely to log some malicious data and could lead to an exploitation.
A Study of CSP Headers employed in Alexa Top 100 Websites
Introduction
The Content Security Policy (CSP) is a security mechanism web applications can use to reduce the risk of attacks, such as XSS, code injection or clickjacking, by informing the browser that something should be blocked when loading or parsing the HTML content. The CSP header has become a standard metric to improve the security posture of modern applications as most application security tools would likely flag a security issue in your applications if it detects the absence of the CSP headers.
How Content-Security-Policy Works
Recently I was tasked to add a CSP header to one of our applications to ensure it is fully equipped to combat some potential XSS issues. After spending a while investigating which CSP policies would be a good candidate to use, I found it is not an easy task to implement a thorough CSP header while avoiding breaking legitimate site functionality. Then I decided to check how other popular web applications are utilizing CSP headers and how I could learn from them to build a robust CSP header.
How Alexa Top 100 websites are adopting CSP header
I started to evaluate How Alexa Top 100 websites are adopting CSP header to harden its security posture by checking whether these websites are adding CSP headers and analyzing whether these CSP headers are really useful to protect against some common attacks, such as XSS and Clickjacking. When analyzing the CSP headers in these top websites, I was using Google CSP Evaluator to check how each CSP directives are defined in the CSP headers besides manual testing. The result is kind of bittersweet as there are some unexpected behaviors and implementations of CSP headers on these top websites. Below are some findings worthy to be mentioned
Findings
Finding 1: 51 out of Alexa Top 100 websites have CSP header added
Though I was expecting that every website in Alexa Top 100 websites should have CSP header implemented by considering these websites attract millions of users on a daily basis, it turns out only 51 websites out of Alexa Top 100 have CSP headers enabled in the web application.
Right, more than 50% of the websites are at least using CSP headers (some of them are use Content-Security-Policy-Report-Only), that is not that bad comparing to the statistics, less than 4% of URLs are carrying CSP headers by referring to a Google Research works.
But if you get a closer look at the CSP headers employed in these 51 websites, some of them are only used to protect against Clickjacking attacks, some of them are using the CSP header as Report-Only mode. The worst part is that most of these CSP headers are not implemented correctly to mitigate potential attacks due to misconfiguration.
Finding 2: More than half of the websites are suffering from common CSP misconfiguration
Misconfiguration 1: ’unsafe-inline’ keyword without specifying a nonce defined in script-scr directives
According to Google research ‘unsafe-inline’ within script-src directive is the most common security misconfiguration for Content Security Policy (CSP) and 87.6% CSP employed the ’unsafe-inline’ keyword without specifying a nonce, which essentially disables the protective capabilities of CSP against XSS exploitation.
There are 34 websites where ‘unsafe-line’ is specified under script-src directive in the CSP configuration. Whereas, 18 out of these 34 websites (roughly 50%) are using the ‘unsafe-inline’ keyworks without specifying a nonce or a hash, which means the CSP header is not configured in a correct way to mitigate XSS exploitation.
This finding is really astonishing as it means around 50% of these 34 heavily visited websites (including facebook, ebay, shopify) are not configuring CSP header in a correct way. Following is a snapshot where ‘unsafe-inline’ is specified without a nonce in the a CSP header employed by one of the Alexa Top 100.
Misconfiguration 2: data: URI schema is allowed in some directives
While around 50% of CSP employed the ‘unsafe-line’ keyword without specifying a nonce, there is another misconfiguration scenario where data: URI scheme is allowed for script-src, frame-src, object-src directive, this misconfigure also defeats the XSS protection of CSP header.
Around 25% of CSP headers employed by the Alexa Top 100 websites are using data:uri under its script-src, frame-src or object-src directives (or default-scr directive when script-src directive is missing). For example, the following XSS attack is utilizing data:uri schema to pass malicious javascript code under your application
Misconfiguration 3: object-src directive allows * as source or is missing (no fallback due to absence of default-src)
In some CSP headers employed by the Alexa Top 100, * (wildcard) is used in object-src directive or default-src directives, which significantly reduce the protection of CSP header as there are multiple ways to inject malicious javascript code when * is used for these directives.
The following CSP header is extracted from one of website
These misconfigurations do not mean the CSP header is not effective at all though these misconfiguration makes CSP protection weak, even useless in some cases.
Finding 3: Some minor issues are ignore in the CSP headers
Ignored issue 1: unsafe-inline are widely added without nonce for style-src directive
Most security engineers downplay the potential security risks imposed by inline style, which is perfectly proved by the data we collected by reviewing CSP header in Alexa Top 100 websites. Among the CSP headers employed by these websites, much more CSP headers are allowing inline style compared to allowing inline script
NO. of websites using unsafe-inline keyword without nonce under script-src directive
16
NO. of websites using unsafe-inline keyword without nonce under style-src directive
22
Though allowing inline style is not as bad as allowing inline script without a nonce, inline style could open the door for a number of attacks like injecting a css keylogger to steal sensitive data. It means, it still makes some sense to add nonce under style-src directive to prevent potential attack by using inline style
Ignored Issue 2: No Access Control or throttling method added to the report-uri endpoint to preventing malicious user from abusing it
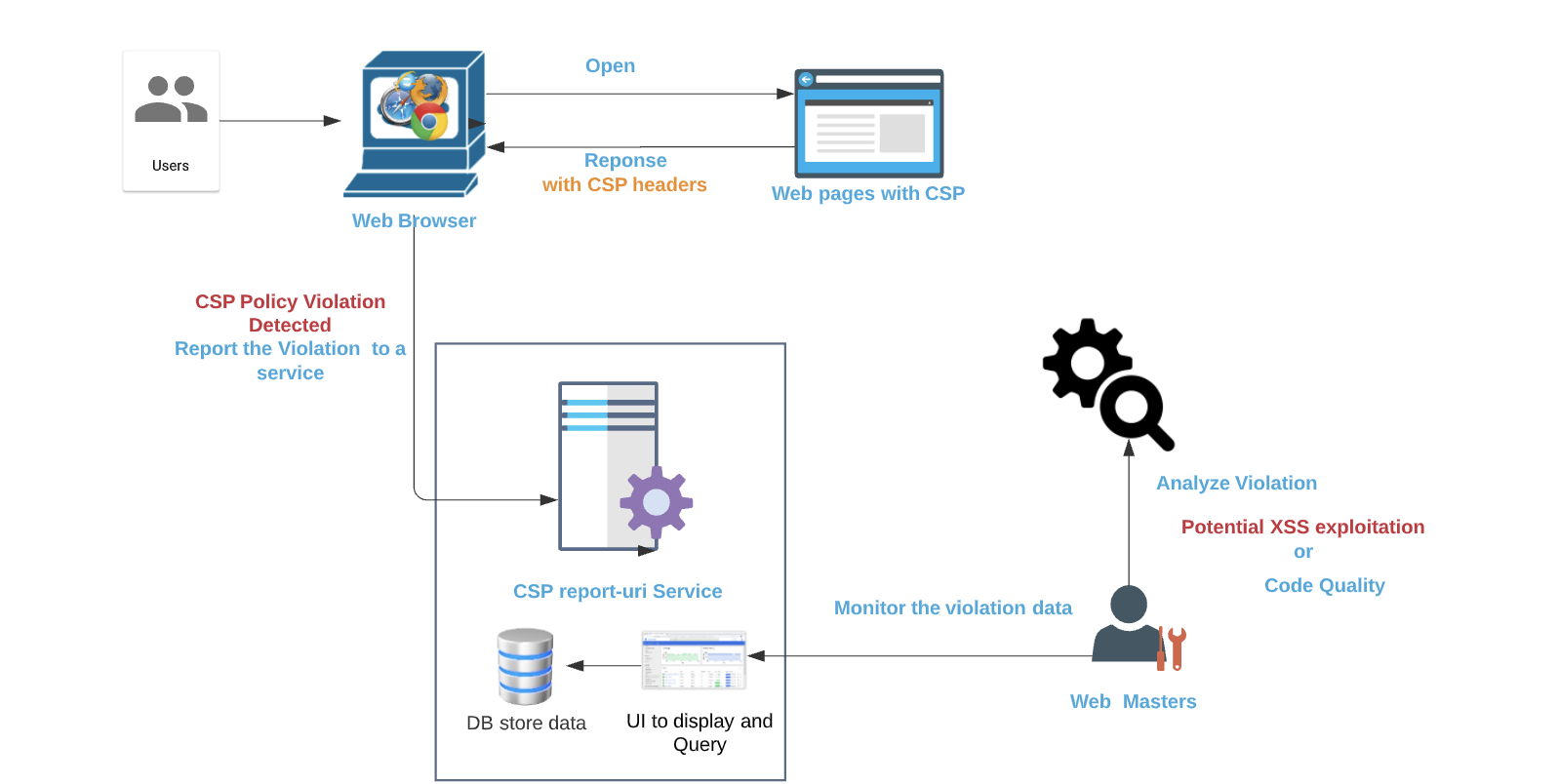
The ‘report-uri’ is a very powerful feature built into CSP that allows website adminstrator to gain insight on their deployed policy by instructing the user agent to report attempts of violating the CSP to the report uri endpoint . You can enable CSP’s reporting feature by specifying the URL of your reporting endpoint with a report-uri directive in your policy. Take the CSP header employed by instragram.com for example, all the violation of CSP policy will be reported to https://www.instagram.com/security/csp_report/
There are many benefits of enabling a report-uri directive for CSP as the CSP violation report might indicate some attempts to bypass or violate your CSP policy to exploit some vulnerability. But this feature also introduces some concerns due to the way how the report-uri endpoint is implemented.
One concern is that any users could send massive invalid CSP violation reports to the report-uri endpoint as most of these report-uri endpoints have no access control or throttle method to prevent this kind of attack. Due to the massive invalid CSP violation, it may make it really harder to spot legitimate attempts to violate CSP policy. In some scenarios, if the report-uri endpoint is not scalable and a high volume of invalid CSP violation report could cause DOS of the endpoint.
CSP itself is a very rich feature as it has a dozen of directives that a user could specify. I am pretty sure that you would spot some other funky or interesting implementations of CSP implementations under the Alexa Top 100 websites. Besides that, to define a robust CSP policy without breaking the applications is not that easy. For example, some disallowing inline script CSP policy could break desired features of jQuery. That could explain why these top tier websites.
Conclusion
While CSP could be very helpful as a part of a defense-in-depth strategy, your application should not completely rely on the protection of CSP headers as a sole defensive mechanism as misconfigurations could make the protection being bypassed easily. The CSP data collected from the Alexa Top 100 is just a tip of the iceberg. I believe there are much more misconfigurations in the wild.
Applying a DAST tool or SAST tool to find potential vulnerabilities, for example, XSS and Clickjacking, and eliminate them is the most efficient solution as CSP header does not eliminate the security flaws but make the exploitation hard.
When building modern API endpoints for your customers, how to keep API keys secure is likely to be the most crucial question to ask at the initial phase of designing your APIs. Though there is no silver bullet for this question as you need to consider the nature, usage and requirement for your API endpoints, there are still some checklists you could refer to help you to avoid or reduce the potential security risks.
Taken from https://www.cyberark.com/resources/
Checklist 1: Identify the usage of your API Keys
Before you could implement your API keys in a secure way, it is vital to figure out how your API Keys are going to be used by your clients. Is your API key just an identification string for your server to identify and log the API activity for an App. Or the API key is used for authentication purposes. Based on the usage for the API keys, different security concerns and the corresponding controls should be evaluated.
API keys are mostly used for App (mobile App, or web application) Identification, Application authentication. In some scenarios it could also be used for user authentication (though it should be called access token rather than API keys in most of these scenarios, to be precise).
API Key Application Identification
API Keys are typically used to identify the application that is making a call to this API. In this scenario, it is very likely this API Key will be left in your application and they are pretty easy for any users to spot and extract these kind of API keys.
Take the widely used Google Analytics API for example, just open some major websites using google analytics tool, you should be able to spot the Google API Key in the source code very easily. Below is a screenshot of an application using Google API Key
As API Keys for application identification are just used for App identification purpose, these keys will be a) residing in the applications and it should b) not bear permissions to perform any sensitive operations. Due to these nature of this kind of API keys, we need check how we could make the API Keys hard to extract from you application and ensure restriction is implemented for this API Keys. Details would be expanded under Checklist 3.
API Key for Application Authentication
API keys could be used for project authentication as well. When a request with this API key reaches the backend. The backend will check whether the calling application has been granted access to call the API and has enabled the API in this project.
As opposed to the API for project identification, this kind of API key is not publicly accessible. Only limited users under this project have access to this API key and then use this API key to perform some sensitive operation with the API . One typical use case is that, this kind of API key could only be retrieved after a user passes the authentication check (for example, the API could be generated under the dashboard after an authenticated user logs in).
Since these API keys are bearing authentication characters and could be used to perform sensitive operation, it is important to understand 1) how this kind of API keys could be accessed, are there any protection implemented 2) Is correct permission is granted to these API keys? Details and some real use cases will be explained in the following section.
API key for user authentication
In some scenarios, the API key can also authenticate users -verifying the person making the call is actually the person they claim to be. Different from API key for App authentication, each user is granted with an API key for a more granular access control rather than an identical API key for the entire App. We will not unfold the security concerns for this kind of API Key (authentication token) because it is kind of totally a new different story.
For the API keys used for App identification, we could not really control WHO could access this kind of API key, but just to make it harder for unauthorized users to extract and access it as this kind of API keys has to be part of your App.
Checklist 2: Check who could access the API keys for App authentication
However, for API Keys for app authentication, these API keys are not supposed to be publicly accessible. We could control who could access these API keys. That is exactly the common security risks that I observed when performing penetration testing, missing correct access control to restrict who could access the API Keys. I will use
For example, a project has a group of users with different roles, such as admin, coordinator, team users and only the admin users are supposed to extract and access the API key for this project. However, in many cases, a user under the App with no permission to access the API keys is still granted permission to access the API Keys due to lack of correct access control or mis-configuration. The following two use cases are real use cases that I found and reported under two private Bug bounty program.
Both use cases are discovered in two private bounty programs and fixed after reporting them.
Checklist 3: Deploy methods to reduce the attacking surface for API Keys for App Identification
For API keys residing in the APP, it is not a matter of if the API keys could be stolen or accessed by a potential malicious user, but how much effort to steal it is worth the return, regardless of your efforts to hide it. However, there are still some ways to reduce the potential attacking surface.
Make it harder for un-authorized user to extract the API Keys from your App
We could not really remove the API Keys from our app completely, otherwise the App will not be able to make API calls to the API endpoints. We could reduce the risk by making it harder for unauthorized user to extract it from our App. Under this security blog post, the user listed several ways to improve the API Key security by
using hash-based message for each HTTP request to avoid setting API Keys in the HTTP requests
Hide the API Keys in the source code by using Code obfuscation
Not store API Keys on the device storage.
Apply API Key Restriction
When using API Keys for APP Identification, it is assumed that these API Keys are ONLY used as an identifier when performing any API calls, it should not be granted permissions to operate some sensitive data. However, that is another common API Keys implemented we observed. For example, some APIs provided by analytics software, it is told the API Keys are just used for identification purpose when sending API requests to the API endpoints, no sensitive operation or malicious API requests could be performed with this API Key even though a malicious user steal the API Keys, it turns out, the API Key could be used to change the App configuration and setting.
To ensure the API Keys are implemented correctly, the developers should restrict the API Keys usage and permissions especially when the API Keys are intended to be used as identifier, not for app authentication.
Conclusion
API Keys are generally not considered secure and they are typically accessible to the clients, which makes it easy for someone to steal an API Key. Since API Keys could be implemented and used in different purpose, you’ll need to consider a variety of factors during the implementation. The above checklist is just the beginning to help you to avoid some common API Key security risks, there are more best practices you could find in the security field.
JSON Web Token (JWT) is an open standard (RFC 7519) that defines a compact and self-contained way for securely transmitting information between parties as a JSON object. JWT are widely used in authentication,authorization and information exchange. Among these use cases, the most common scenario for using JWT is for authorization purpose. Once a user is logged in, each subsequent request will include the JWT, allowing the user to access routes, services, and resources that are permitted with that token. You may start to ask why not using Session token. One reason is that the JWT is stateless compared with Session tokens, it means that the server side does not have to store the JWT in a centralized DB to perform the validation when a clients sends a request to the server, whereas, the server has to store the session cookies for validation purpose.
To understand the common implementation mistakes of JWT, we need first figure out the structure of the JWT token as most the implementation errors are caused by misunderstanding the structure of JWT token and how each component of JWT are used for.
Structure of JWT Token
A well-formed JWT consists of three concatenated Base64url-encoded strings, separated by dots (.):
Header : contains metadata about the type of token and the cryptographic algorithms used to secure its contents. For example
Payload : contains verifiable security statements, such as the identity of the user and the permissions they are allowed. An example of the payload could be
{
"username": "test@example.com",
"id": "new user"
}
Signature: it is used to validate that the token is trustworthy and has not been tampered with. When you use a JWT. Signature is piece of encrypted data of the Header and Payload date by using certain encryption method (such as HMAC,SHA256) with a secret which should be residing on a server side.
JWT itself is considered as secure method. Most of the security issues discovered against JWT are caused by implementation mistakes.
Leak the secret key
JWT is created with a secret key and that secret key is private to you which means you will never reveal that to the public or inject inside the JWT token. However, sometimes, the developers could mistakenly leak the signing secret to public. For example, the JWT signing secret is stored on a client side javascript functions or stored on a public accessible files. As a consequence, an attacker could bypass the signature verification easily as the attacker could sign any payloads with the secret to put the server side signature validation in vain. Here is one example listed under Hackerone where the developers are adding hardcoded secret in the client side javascript file.
Using Predictable secret key
It is also possible that the developers are copying a piece of code from a sample code base when implementing the JWT on the server side or they are using a simple word (not randomly generated complex string) as the secret value when implementing the JWT on the server side . A brute force attack could easily extract the secret key as the attacker knows the algorithm, the payload with the original information and the resulting signature of the encrypted payload and header. One example listed under Hackerone shows how a developer is using the ‘secret’ as the secret when implementing the JWT on the server side.
Broken JWT Validation
There are numerous way how the JWT validation could be broken during insecure implementation. Here are some typical examples where a broken JWT validation could happen.
Not Validate Signature at all. Some developers implement the JWT validation in a wrong way, where they only decode the JWT payload part without validating the signature part before accepting the JWT as a valid token.
Not Validate the JWT correctlyif None alg is provided. An attacker could or creates a token by setting alg (the signing algorithm) to None in the header. If the server side is NOT validating whether the None alg was really implemented when the JWT was generated. As a consequence, any JWT provided by the attacker with a None value to the alg will be treated as a valid token. To prevent this, the server side should check whether the alg value is the one when the JWT token is generated. If not, the JWT should be treated as an invalid.
Not Validate the JWT correctly when alg is changed to HS256 from RS256. HS256 is a symmetric encryption method, the server side is using the same key to generate and validate the JWT. Whereas, RS256 is an asymmetric encryption method, the JWT payload was signed with its private key and validated with the public key, which is known to the public. Now An attacker creates the token by setting the signing algorithm to a symmetric HS256 instead of an asymmetric RS256, leading the API to blindly verify the token using the HS256 algorithm using the public key as a secret key. Since the RSA public key is known, the attacker can correctly forge valid JWTs and bypass the validation method.
Lack of kid header parameter validation
The kid (key ID) Header Parameter is a hint indicating which key was used to secure the JWS. This parameter allows originators to explicitly signal a change of key to recipients. With the key identifier, the consumer of a JWT can retrieve the proper cryptographic key to verify the signature. This simple mechanism works well when both the issuer and consumer have access to the same cryptographic key store.
Since the attacker can modify the kid header parameter, attacker can supply any values in there when it is sent to the sever. If the server is not validating or sanitizing the kid value correctly, it could lead to severe damage.
For example, the kid value in the JWT header is specifying the location of the JWT secret to sign the JWT payload
For example, the kid value in the JWT header is specifying the location of the JWT secret to sign the JWT payload
{
"alg": "HS256",
"typ": "JWT",
"kid": "http://evil.com/privKey.key" //Private key supplied by the attacker
}
Now, if the attacker is providing his own private key to the kid parameter and adjust the JWT token, he would be able to generate any valid JWT token.
Other wrong implementation
The above implementation mistakes could lead to very severe security issues, for example, account hijacking and authentication bypass. There are some other implementation bad practice should be avoid when using JWT token.
Use JWT token as session cookie. Some applications are using JWT token as a session cookie and it could cause havoc. Let’s say you have a token and you revoke it due to a user logout or any other action, you could not really invalidate the token before its expiration has been reached unless you keep a DB to store these tokens and build a revocation list, which is not the intention of using a stateless JWT.
Leak the JWT in referrer header. It is common that a developer attaches the JWT in a URL, for example, user registering and password reset service, and the HTML page of the URL are loading some 3rd party web pages. As a consequence, the JWT could be leaked to 3rd party web pages via referer header if noreferrer is not probably deployed in the web application.
Conclusion
JWT are adopted by more and more applications over the web. If used correctly, it could help you to build a robust and agile authentication, authorization and information key functions.However, if misused or implemented incorrectly, this technology may put entire systems at risk. This JWT Security Cheat Sheet provides an overview of all these best practices when using JWT in your applications.